
Labeling Election-Related Communications on Social Media: Navigating “easy” and “hard” Labels
By: Thessalia Merivaki, Ph.D., Associate Teaching and Research Professor, McCourt School of Public Policy, and Jorge Bris Moreno ’25, MDI Scholar
Researchers analyzing social media data commonly struggle with thematically labeling content. While organizing content using pre-identified keywords can target specific concepts under investigation, social media posts – whether text or multi-modal – typically contain nuances that automated methods miss. Human coding can capture these subtleties more effectively, but requires structured protocols to maintain inter-coder reliability and construct validity. This raises a key question: How can we best combine algorithmic and human approaches to optimize content labeling?
Labeling election-related communications: easy and hard labels
Since the 2020 U.S. Presidential election, my research team and I have been tracking and labeling communications shared by state and local election officials on mainstream social media platforms like Facebook, Instagram, and X (formerly known as Twitter). We are interested in capturing what type of information election officials share with voters to educate them about how to vote and how elections are kept safe and secure. We are also interested in capturing how information is shared (text, multimodal) and whether it is accessible to different audiences (multilingual voters, voters with visual impairments).
To do this, we designed a hierarchical, nested taxonomy of 120 labels, which aim to capture election processes and voting methods (voter registration, mail voting, ballot counting, post-election audits, among others), information about election deadlines and polling places, as well as information about election security and election law. We also include a series of labels that aim to identify communications designed to build trust in election integrity, which we describe as “trust-building.”
Working with the Algorithmic Transparency Institute and their platform Junkipedia, we have been able to manually label this content, by assigning the relevant labels to each post we review. In the 2024 election cycle (September – December 2024), we collected over 13,000 posts shared by state election officials., and over 60,000 posts shared by local election officials across all states and D.C. Our team consists of two faculty members and five research assistants. The veracity of the human-coded data, which was used as a baseline for the accuracy of the other methods, has been held to maximum standards by setting a minimum agreement baseline among coders, where the different sets of social media posts were coded over four practice rounds.
Human coding has several benefits: It guarantees human review of content, allows coders to capture information communicated both in text and visuals, and helps identify limitations in labeling schemas, which can be remedied in real time by revising the codebook. To do this, coders also need to be somewhat familiar with the population they track, as well as the subject, in this case election officials and election administration. Very importantly, coders need to be familiar with the context around election-related communications: Election officials share information about how to vote, but they also share information to pre- and de-bunk misinformation, reassure voters that elections are secure, and explain which safeguards are in place to ensure that votes cast are counted accurately.
Some of this information is “easy” to label. For instance, a post shared on Facebook that informs voters about an upcoming voter registration deadline or how to register to vote is labeled as “voter registration,” which is one of our labels, since voter registration is a key process for a U.S. to vote (Figure 1). Similarly, a post about how to request a mail ballot is labeled as “mail/absentee voting,” which we also consider an “easy” label.
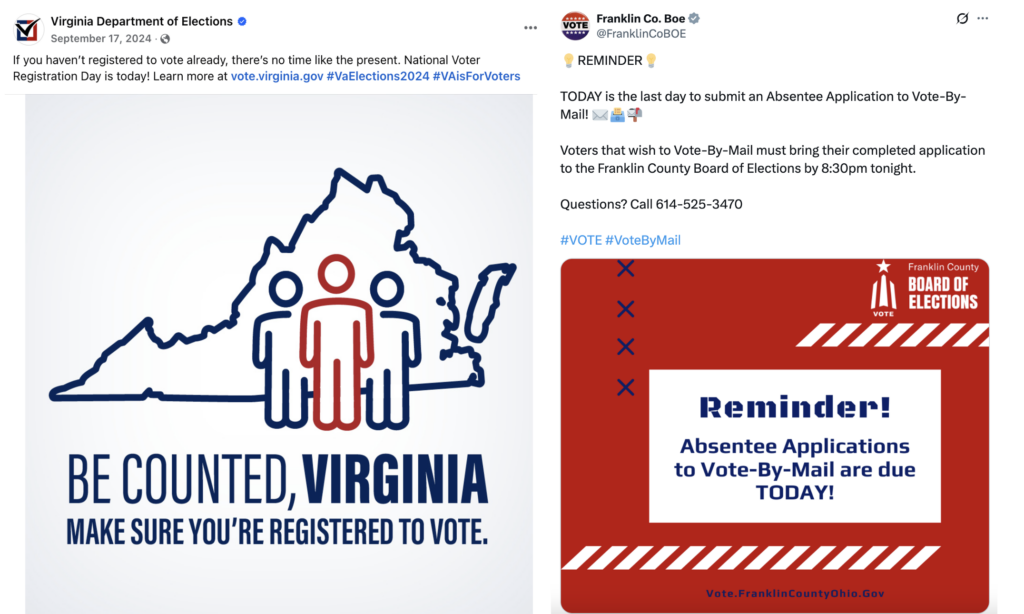
Figure 1. Voter registration and Mail voting labeled posts.
Some of the information, on the other hand, is “hard” to label, because the message is not explicitly communicated, or because it is communicated with specific signals. We consider trust-building a “hard” label because it is designed to capture both explicit and implicit communications that extend beyond keywords. Our knowledge of what constitutes a trust-building message is grounded on our work during the 2022 U.S. midterm cycle and our conversations with election officials about their trust-building strategies. Trust-building messages are those that communicate to voters that elections are secure, safe, and produce accurate election results. They include references to election integrity, voter confidence, and election security. They communicate that election officials are trusted sources of information, and that election staff and workers are professionals, and part of a voter’s community, their friends and neighbors. Some of these communications include trust-building hashtags such as #TrustedInfo, or #YourVoteCounts. Some include an office logo that says “Trusted.” (Figure 2).

Figure 2. Examples of Trust-building Communications
Using Supervised Machine Learning to code “hard” labels
As of April 2025, 100% of the state election officials posts have been labelled (and about 45% of local election official posts have been labelled, underscoring that human coding is a labor-intensive process. It is a reasonable strategy, therefore, to explore leveraging machine learning to automate the coding process, and investigate how human and automated coding approaches can yield high accuracy rates, imposing a strong assumption that the “ground truth” lies in human coding.
Given the sparsity of our labeled data and the fact that our labels are non-exclusive, we train separate supervised learning models to classify each label as either True (present) or False (not present). This approach allows us to finetune the models specifically for each label, hoping for a better classification than training multi-label classification models. Since the labels follow a nested structure, when a label is classified as True, the models for its directly related labels are also triggered; otherwise, they are skipped. To explore this approach, we start by training models for labels we identify as “easy” (voter registration) and “hard” (trust-building). Our expectation is that our models will accurately classify content labeled as “voter registration” at higher rates than “trust-building.”
We categorize our models into three groups: Classic Machine Learning Models, which rely on traditional statistical learning and feature-based approaches (e.g., XGBoost, Random Forest, SVMs); Pretrained NLP Models, which involve fine-tuning transformers such as DistilRoBERTA and Electra; and Custom Deep Learning Models, designed specifically for our classification task. For each group, we train multiple models to identify the best-performing one, evaluating key metrics such as the F1 score. Additionally, we analyze true and false positives and negatives to gain deeper insights into model performance and potential areas for improvement.
Challenges and next steps
Due to our heavily imbalanced labels – where most posts do not contain the target label – many machine learning models tend to develop biases toward the dominant classes, as predicting the most frequent class often leads to higher overall accuracy. To mitigate this and balance the prediction errors across classes, we apply weighted loss functions, resampling techniques, F1 score tracking instead of overall accuracy, and balanced weighting across our training, validation, and test sets. However, our exploration revealed that we lack sufficient data for certain models, particularly for fine-tuning pretrained transformers. Moreover, while we achieve over 90% accuracy for “easy” labels, our performance on “hard” labels remains significantly lower, as we struggle to maintain a balance between true and false positives and negatives.
Based on these findings, we aim to continue refining our approaches, focusing on improving performance for “hard” labels and expanding the range of labels we seek to automate. Notably, our Custom Deep Learning Models have shown great potential in achieving a balanced performance across both positives and negatives, with CNN- and LSTM-based methods unexpectedly outperforming more sophisticated approaches such as transformers. Additionally, we plan to experiment with multi-label models to explore potential relationships between different labels. Once our process is complete, we intend to develop a robust pipeline for automated labeling and publish it on Hugging Face.
Furthermore, we are committed to making our data publicly accessible by publishing it in an open database. We also plan to share our methodology in a public repository to provide a valuable resource for researchers.
Thessalia Merivaki, Ph.D. is an Associate Teaching Professor at the McCourt School of Public Policy and an Associate Research Professor at the Massive Data Institute.
Jorge Bris Moreno ’25 is an MDI Scholar and a graduate student at Georgetown Graduate School of Arts & Sciences in the Data Science and Analytics Masters of Science program.