
Creating an Open Source National Dataset of National Drinking Water Funding
How to turn 50 PDFs into actionable data.
Access to clean drinking water is widely considered a basic human right. In the United States, the Environmental Protection Agency (EPA) oversees the projects that guarantee this right. The EPA allocates money to each state as State Revolving Funds (SRFs), and each state assigns funds to drinking water projects according to a Project Priority List (PPL) that the state government develops.
Unfortunately for anyone who wishes to investigate water funding, project spending information has historically only been available reports, reports that are not ready for analysis and differ from state to state. This lack of a national accessible spreadsheet for water funding information posed two issues for MDI to tackle:
1) How do we convert state project reports into analysis-ready data?
2) Once in a usable format, how do we harmonize data from different states?
Analyzing state water project spending is crucial to identify potential disparities in funding across different types of communities. Each PPL ranks each project proposal according to varying sets of metrics, such as its effect on public health or the income status of those served by the proposed project. Projects that have a high impact on public health or that serve a low income community typically are given higher priority as many states put a premium on projects that affect public safety or address a historical disparity. Ensuring that disadvantaged areas get their fair share of funds is crucial in avoiding water injustices like the lead issues that plagued Flint, Michigan over the last decade.
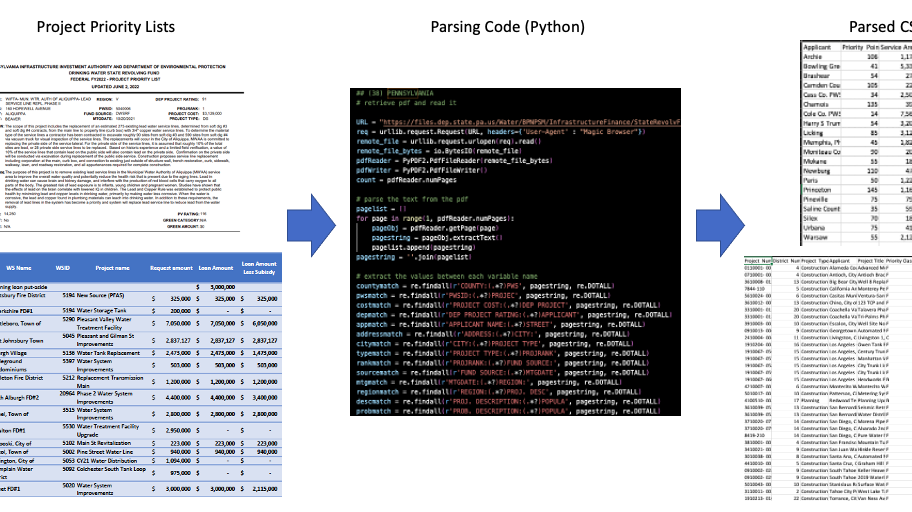
The diagram below illustrates how the EIDC team parsed the state reports into usable and harmonized data sets.
Parsing PDFs to make data readily accessible in a machine-readable format
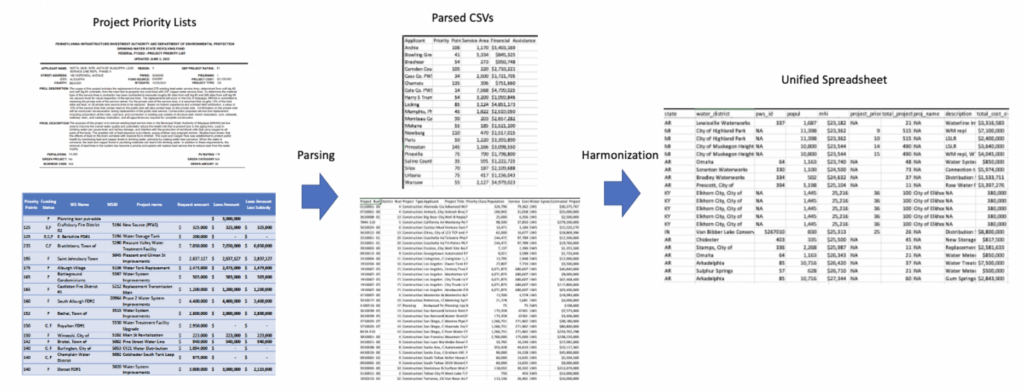
Diagram illustrating the overall process described in this post

Diagram indicating overview of the parsing process
The first of MDI’s two tasks was to parse the data from each state’s PDF into a CSV. We developed a Python script that pulls PPLs from state government websites and converts them into CSV files. In some states, this was a straightforward process, but many others posed obstacles, such as Pennsylvania, which posts its PPLs in the format seen below, which is not machine-readable. In order to address this issue with Pennsylvania’s PPL, the script had to be extensively altered to draw the information and convert it into a usable format. With the vast majority of states already completed, this script allows anyone to turn these difficult files into adaptable data sheets with free software. And, as we write code to solve these problems for individual states, we build up a portfolio of code snippets that may prove useful to EIDC users working on past or future water reports or on state level reporting in other domains.
The parsing is useful for anyone investigating equitable water funding in a specific state, but in order to facilitate analysis of spending across multiple states we had to complete a second task: harmonization.

Pennsylvania Project Priority List, in a format unusable for policy researchers
Harmonizing CSVs to compare water funding information from state to state
EIDC team members used R code to harmonize the state level data sets (many with differing sets of variables) into a single spreadsheet. This consisted of coalescing columns with different names but the same meaning (for example, “PWS_ID” and “PWSID”) and manually renaming certain columns that had identical names but different meanings (for example, “Name” could signify water district names in some states and project names in others). The bulk of the coalescing task was done using a custom function I wrote to search for phrases across column names and combine those columns (in this way, inputting the phrase “pws” turns PWS_ID and PWSID into one column). The end result of this task is a table that combines factors common across most or all states, such as population served by the project proposal or the cost of the project, and preserves variables unique to each state so that the state can be researched individually. These tools can be used by a variety of audiences ranging from policy researchers investigating issues of inequity to students writing theses to anyone who simply wishes to learn more about which areas in their community receive funding for water projects.
Using these tools, researchers can finally see who is receiving funding for drinking water projects in every state across the country in a single, machine-readable dataset. If there are any patterns of marginalized communities receiving less funding or being consistently ranked lower in priority lists, those trends can only be discovered now that the datasets are in an analysis-ready format.