
Integrating Data Engineering Principles to ensure data quality and usability of the EIDC
The Massive Data Institute (MDI) is developing the Environmental Impact Data Collaborative (EIDC) to enable community groups, policymakers, and researchers to discover, access, merge, transform, analyze, visualize, and discuss data in ways that support them to make environmental policy more effective and just.
To ensure early usability and long-term sustainability of the EIDC, we prioritize building a cleaning, transforming, and quality-checking pipeline that incorporates a variety of data sources. As the EIDC grows, this process will be refined and modified continually based on feedback. As a data collaborative, it is vital for us to have a unified format across our data so that they can be interoperable and optimized for collaboration.
Guiding Principles: This Extract, Load, and Transform process is designed with three guiding principles: modularity, version control, and standardization.
- Modularity involves separating the process into discrete stages so that any error can be easily tracked, diagnosed, and resolved quickly.
- Version control allows us to track and save copies of data at every stage. By doing so, datasets that go through the process would have multiple versions at different stages. It is easy to roll back to the previous version if a mistake is made
- Unified standards for transforming and quality-checking data in order to make sure the data in EIDC shares the same format so that they can be interoperable.
This collaborative process facilitates multiple parties’ participation and makes the EIDC flexible and robust. The process also contributes to EIDC sustainability because end-users and partners can also contribute to the standards so that the spirit of collaboration is extended from using the data to curating the data.
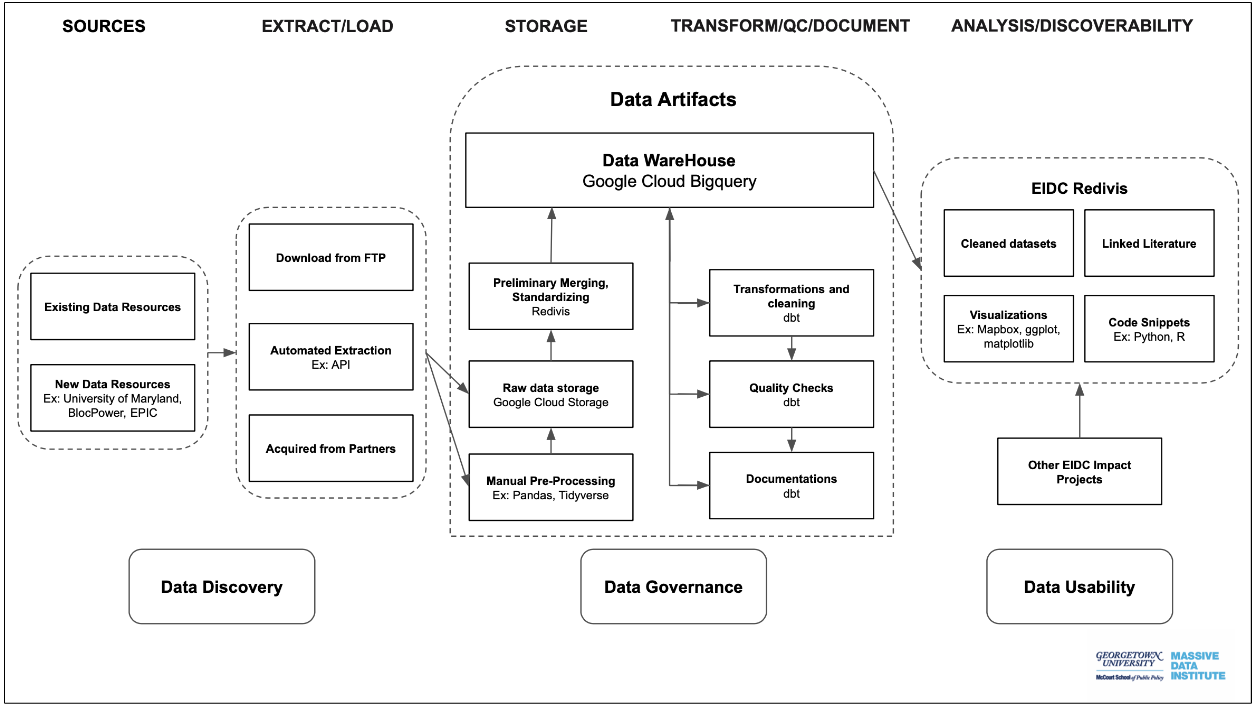
Data Discovery: The process starts with acquiring data. Data from different sources often have different formats that could make data merging and manipulation extremely difficult. For example, census tract Federal Information Processing Standards Codes are 11-digit numbers that uniquely identify each census tract; and the same codes in different datasets can take different forms. In some datasets, the census tract FIPS codes are exactly 11-digits while in others it might have six zeros appended in the front.
Data Loading: After documenting the datasets’ basic information on our internal metadata spreadsheet, the raw data are uploaded into Google Cloud Storage (GCS) as a way to kick off our data ingestion process, as well as a way for us to have a backup of the raw data. The team then performs pre-processing methods such as combining different years of data on the same datasets and other manual transformations. The pre-processed version as well as the code that performs pre-processing are also uploaded into GCS.
Data Transformation: The EIDC team then transfers the data to Google Cloud BigQuery where we use software called dbt to utilize the resources BigQuery provides to test and transform the data. The dbt software adds another layer of modularity to our process and allows us to transform and test the data so as to ease debugging and version control.
The EIDC has set a wide range of standards and best practices for how to manipulate and quality check the data to ensure quality and usability. For example, we transform and standardize geographic coordinates and addresses to the most used format and test each entry so that there are no erroneous data. After that, the cleaned data goes to Redivis, our platform that the EIDC is built on, for release. In Redivis, we also edit final documentation and link related literature to the cleaned datasets.
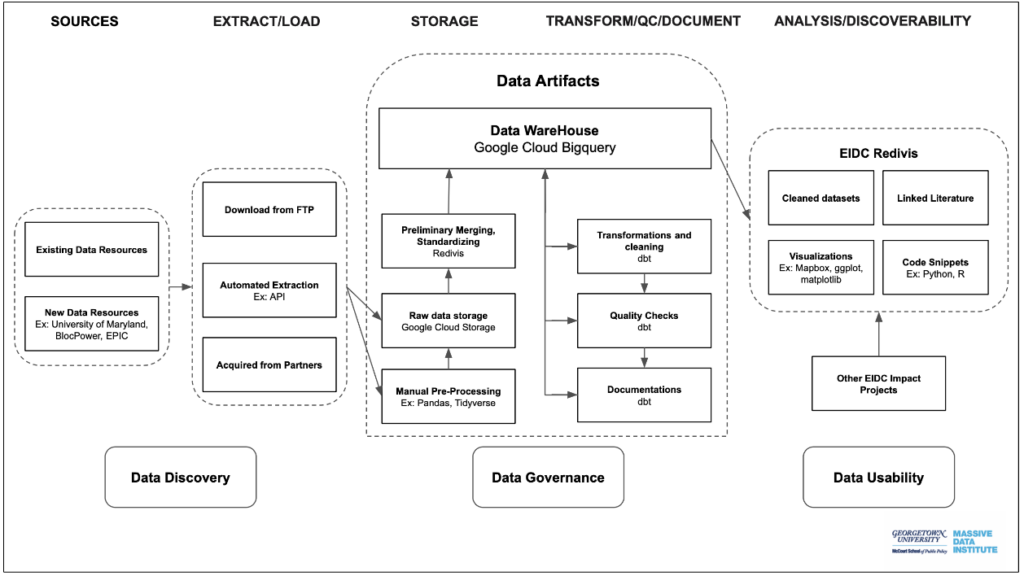
This diagram depicts stages of the EIDC Extract, Load, and Transform process. Tools used and data flow are specified by each box and arrow.
The EIDC tailored modern data engineering and infrastructure principles to its special use case and created a data ingestion process that is flexible, robust, and sustainable. The EIDC is a platform that hosts not only cleaned, easy-to-use data but also impacts projects that utilize data from partners and users of the collaborative.